Course Information
- Professor: G. Fourny
- Credits: 10 ECTS
- Semester: Fall 2025
- Status: In Progress
Big Data is a portfolio of technologies that were designed to store, manage and analyze data that is too large to fit on a single machine, while accommodating for the issue of growing discrepancy between capacity, throughput and latency.
Welcome to my journey through ETH's Big Data course! This is where theory meets reality, and where I'm learning that handling petabytes of data requires fundamentally rethinking everything we know about databases and systems.
The Big Picture Problem
Here's the core challenge that blew my mind in the first lecture:
How do we deal with BIG data? Traditionally, a DBMS fits on a single machine. But Petabytes of data do not fit on a single machine.
As a consequence, in this course, we will have to rebuild the entire technology stack, bottom to top, with those same concepts and insights that we got in the past decades, but on a cluster of machines rather than on a single machine.
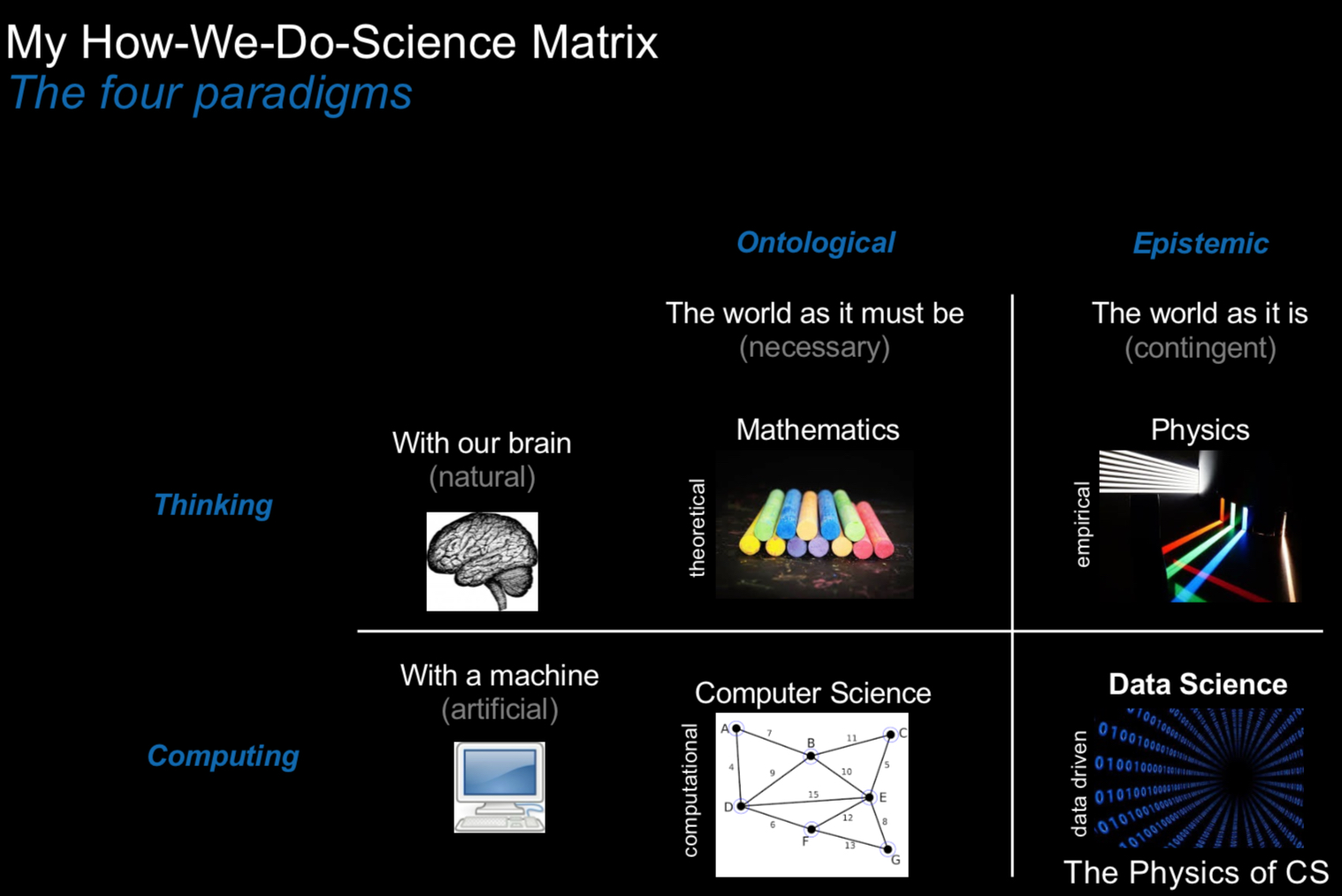
The evolution from single-machine to distributed systems
The Three Vs of Big Data
Everything in big data revolves around three fundamental challenges:
1. Volume 📏
The scale is just insane. We're talking about prefixes that sound like science fiction:
- Terabytes (10¹²) - This used to be "big"
- Petabytes (10¹⁵) - Now we're talking
- Exabytes (10¹⁸) - Google-scale stuff
- Zettabytes (10²¹) - Global internet traffic
- Yottabytes (10²⁴) - Theoretical for now... right?
2. Variety
Data isn't just tables anymore. Modern systems need to handle 5 different shapes:
- Tables - The classic relational model
- Trees - XML, JSON, Parquet, Avro formats
- Graphs - Think Neo4j, social networks
- Cubes - Business analytics and OLAP
- Vectors - Embeddings for unstructured data (text, images, audio)
3. Velocity
This is where things get really interesting. There's a growing distortion between three factors:
Capacity
How much data we can store per unit of volume
Throughput
How many bytes we can read per unit of time
Latency
How long we wait until bytes start arriving
The Solutions: Parallel and Batch
The course teaches us two fundamental approaches to tackle these challenges:
Parallelization 🔄
To bridge the gap between capacity and throughput, we need to:
- Exploit sequential access & parallelism (batch jobs, scans, partitioning)
- Use distribution to overcome single-node throughput limits
- Hide latency with caching, replication, and in-memory techniques
Batch Processing 📦
To handle the throughput vs latency gap, we move from real-time to batch processing that runs automatically and efficiently processes large chunks of data.
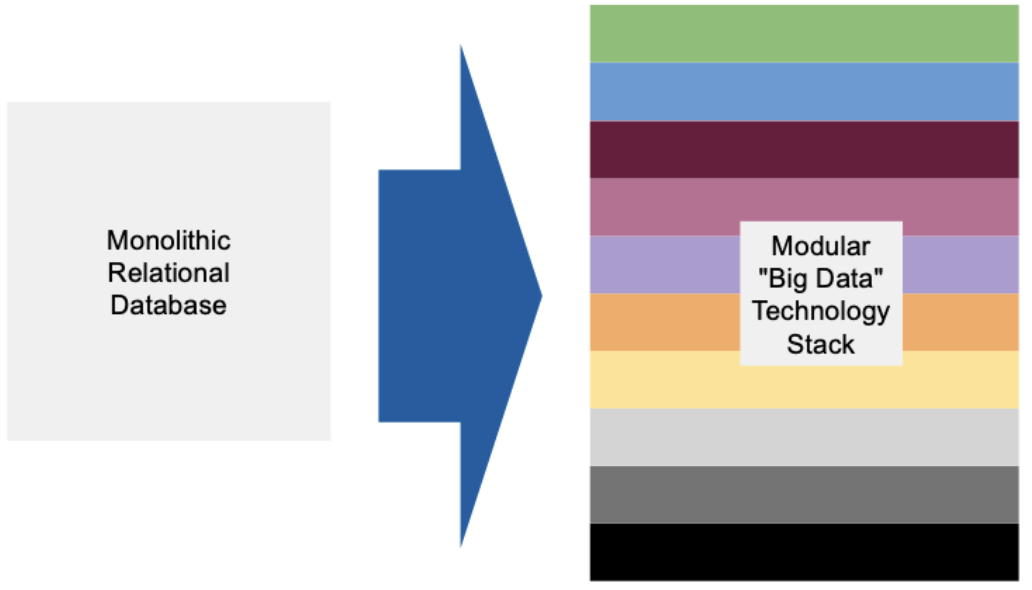
Modern big data architecture - from raw data to insights
Key Technologies and Concepts
The Foundation: HDFS and MapReduce
Pro tip from my notes: Pay close attention to HDFS and MapReduce - they're the building blocks everything else rests on.
The Evolution: From NoSQL to Modern Systems
The course covers the evolution of data storage beyond traditional RDBMS:
- Wide Column Stores - Like Cassandra
- Document Stores - MongoDB and friends
- Key-Value Stores - Redis, DynamoDB
- Graph Stores - Neo4j, Amazon Neptune
Data Independence: The Guiding Principle
Data independence means that the logical view on the data is cleanly separated, decoupled, from its physical storage.
This concept, introduced by Edgar Codd in 1970, is still the foundation of everything we do. Even in distributed systems, we want to hide physical complexity and expose simple, clean models.
The Red Thread 🧵
Here's the conceptual flow that ties everything together:
When the course talks about normalization, models, or declarative queries, I immediately connect it to Spark SQL and JSONiq. This mental framework has been incredibly helpful.
Learning Strategy
Some practical advice for anyone taking this course:
- Focus intensely on HDFS and MapReduce - Everything builds on these
- Connect concepts to Spark SQL/JSONiq - Especially when discussing normalization and declarative models
- Follow the red thread - Always trace from raw data to final query language
- Study 3-4 hours per week - The material is dense but manageable
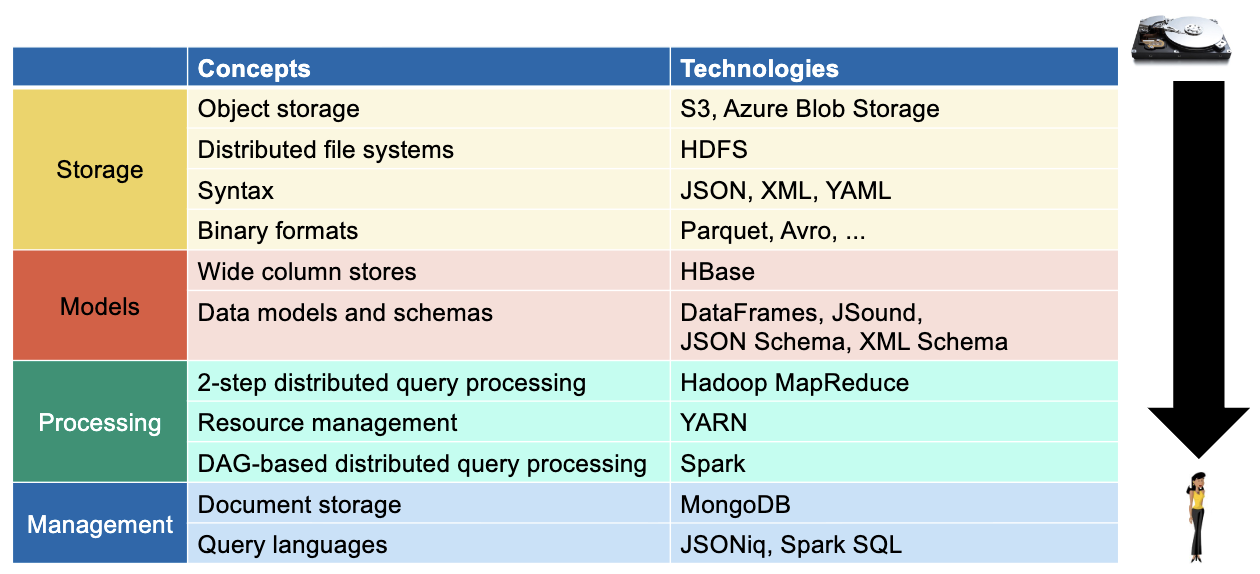
My study schedule and approach for the course
What's Coming Next
As the course progresses, I'll be diving deeper into:
- Distributed file systems and their trade-offs
- MapReduce programming paradigms
- Spark and modern distributed computing
- Data modeling for different shapes (trees, graphs, cubes)
- Query optimization in distributed systems
Final Thoughts
This course is fundamentally changing how I think about data systems. The realization that we need to "rebuild the entire technology stack" for distributed systems is both daunting and exciting.
It's fascinating to see how the principles from traditional databases (like data independence) still apply, but require completely different implementations when you're dealing with clusters instead of single machines.
The 💽 emoji in my course notes isn't just decoration - it represents this massive shift from single disks to distributed storage that's reshaping the entire field of data management.
More updates to come as I progress through HDFS, MapReduce, and beyond!